Why should you understand the basics of CPU architecture?
Let’s start with a simple puzzle. Which loop will end first?
double[] a = new double[8000000];
for (int i = 0, n = a.length; i < n; i++) {
a[i] *= 3;
}
for (int i = 0, n = a.length; i < n; i+=8) {
a[i] *= 3;
}Both loops process the exact same array and do the same, but the second loop processes every 8th element. Based on this we could predict the second loop needs only 1/8 of the time…
Benchmark results:
Benchmark Mode Size Score Error Units
CacheMissBenchmark.computeAllElements avgt 8000000 4,907 ± 0,019 ms/op
CacheMissBenchmark.computeOneElementForEachCacheLine avgt 8000000 4,936 ± 0,112 ms/op
Both loops need almost the same amount of time. The differences are negligible. In order to understand this behavior, we need to consider modern CPU caching.
CPU and Caches
In order to process the data, the CPU has to access the memory. Although accessing main memory is expensive and time consuming. CPU uses caching for hiding this memory latency.
Typically the CPU has 3 levels of cache. Each cache level differs in size, access time, and number of CPU cycles in order to access data.
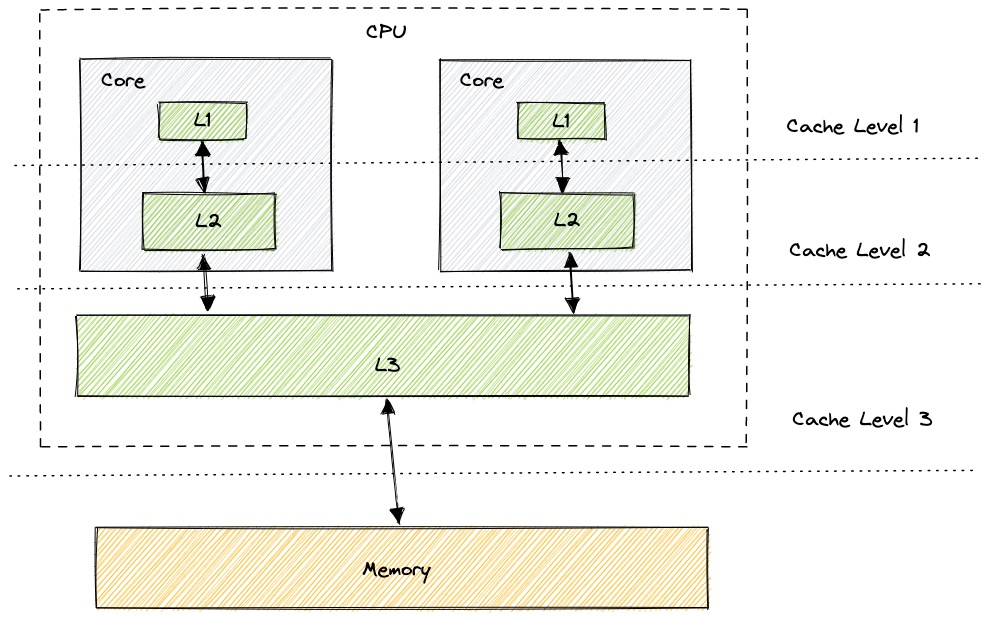
Differences in cache levels based on Intel Haswell architecture:
| Cache level | Size | Number of cycles | Latency |
|---|---|---|---|
| Level 1 | 64 KB (32 KB data cache + 32 KB instruction cache) | ~4 cycles for simple access via pointer | ~1 ns |
| Level 2 | 256 KB | 12 cycles | ~5 ns |
| Level 3 | 8 MB | 36 cycles (3.4 Ghz i7-4770) | ~25 ns |
Cache line
CPUs use multiple different caching strategies. Instead of loading just one variable to the cache, processors tend to load a few more values. This chunk of data is called cache line - the unit of data transfer between cache and memory. In order to improve throughput, CPUs use spatial locality: the concept that likelihood of referencing a resource is higher if a resource near it was referenced.
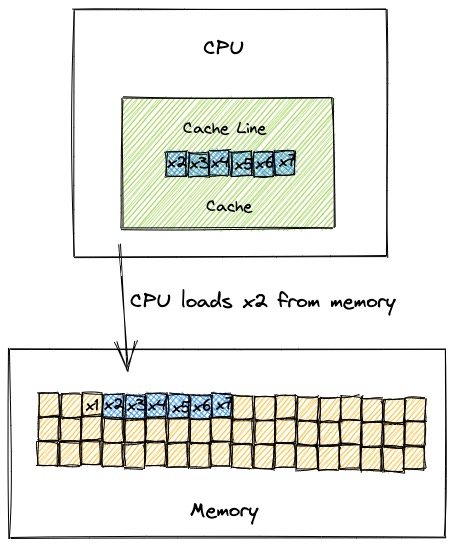
In this particular case, the CPU loads multiple array elements to the cache at the same time. As we already know, reading data from CPU’s cache is extremely cheap compared to reading data from the memory. Also, the cost of processing each element is negligible (a[i] *= 3). Due to this, the total cost of the loop is equal to the number of loading cache lines from memory. Processing times of both loops are almost the same because CPU needs to load the same number of cache lines.
Conclusion
- sometimes your hardware may have significant impact on your system
- remember about the cost of cache misses
The examples are available on my GitHub Account.
Resources
- http://norvig.com/21-days.html#answers
- https://www.extremetech.com/extreme/188776-how-l1-and-l2-cpu-caches-work-and-why-theyre-an-essential-part-of-modern-chips
- https://www.makeuseof.com/tag/what-is-cpu-cache/
- https://www.7-cpu.com/cpu/Haswell.html
- https://gist.github.com/jboner/2841832