False Sharing
False sharing is one of the well-known performance issues on multi-core systems, where each cpu has its local cache. False sharing is very hard to detect because the threads may be accessing completely different global variables that happen to be relatively close together in memory. Like many concurrency issues, the primary way to avoid false sharing is careful code review and aligning your data structure with the size of a cache line.
The beginning
CPUs use multiple different caching strategies. Instead of loading just one variable to the cache, processors tend to load a few more values. This chunk of data is called cache line - the unit of data transfer between cache and memory. In order to improve throughput, CPUs use spatial locality: the concept that likelihood of referencing a resource is higher if a resource near it was referenced.
When two or more different threads read the same part of the memory, they may end up loading the same data to its caches. Cache coherence is the process of maintaining consistency of shared resource data that ends up stored in multiple local caches.
False Sharing
False sharing occurs when threads on different processor modify variables that reside on same cache line as shown in the following image:
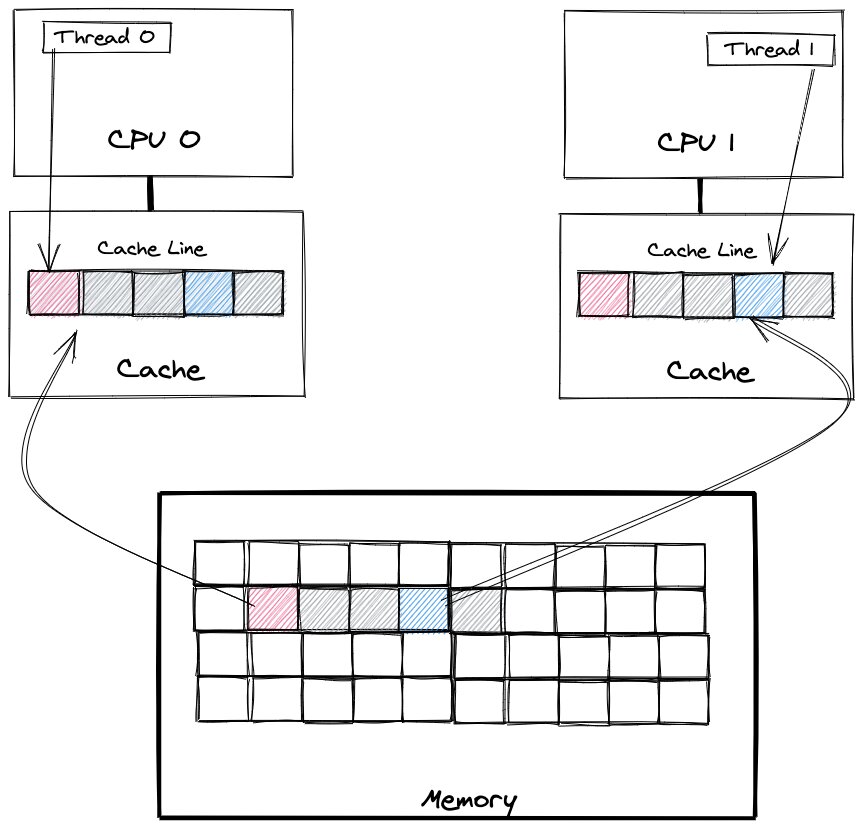
CPU 0 reads the red value from the main memory and CPU 1 reads the blue value from the main memory. We already learnt that the CPU fetches a few more values from the memory and stores them into a cache line.
The problem occurs when CPU 0 changes the read value and then CPU 1 wants to read again the blue value. We might expect that the blue value will be read from cache. Nevertheless, it is not possible due to cache coherence. After CPU 0 changes the read value, the cache line is marked as invalid. CPU 0 is forced to flush cache line to main memory and CPU 1 needs to fetch the latest value from the memory. After flushing and re-reading the cache line from the main memory, both CPUs have the latest cache line version.
This cache miss and additional flush to the main memory can degrade the overall performance, although CPU 0 and CPU 1 don’t use the same memory locations.
Let’s try to reproduce
Java Object Layout (JOL) is a tiny toolbox to analyze memory object layout schemes in JVMs. It allows you to make an estimate of how much memory the object takes.
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>
Let’s see memory class layout for simple class with two long variables:
System.out.println(ClassLayout.parseClass(CounterAffectedByFalseSharing.class).toPrintable());
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 (alignment/padding gap)
16 8 long CounterAffectedByFalseSharing.counterA N/A
24 8 long CounterAffectedByFalseSharing.counterB N/A
Instance size: 32 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
Each class has 12 bytes object header. We need to know that JVM adds enough padding to the object to make its size a multiple of 8. In this case, JVM adds 4 bytes. Additionally, there are two long variables each 8 bytes. In total, each instance size is 32 bytes. So the object fits into my 128 bytes of processor’s cache line. If you would like to check the size of your cache line, you need to invoke:
getconf LEVEL1_DCACHE_LINESIZE
It is already known that this class could be potentially affected by false-sharing. Following benchmark runs two threads. Each thread modifies different variables but variables are loaded in the same cache line, which means the number of cache misses is huge.
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Group("falseSharing")
@GroupThreads(1)
public long incrementCounterA() {
return COUNTER_AFFECTED_BY_FALSE_SHARING.incrementA();
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Group("falseSharing")
@GroupThreads(1)
public long incrementCounterB() {
return COUNTER_AFFECTED_BY_FALSE_SHARING.incrementB();
}The average time of incrementing the counter is around 49 nanoseconds.
Benchmark Mode Cnt Score Error Units
FalseSharingBenchmark.falseSharing avgt 20 48,897 ± 0,763 ns/op
FalseSharingBenchmark.falseSharing:incrementCounterA avgt 20 48,905 ± 0,898 ns/op
FalseSharingBenchmark.falseSharing:incrementCounterB avgt 20 48,889 ± 0,859 ns/op
Solution
In order to reduce the number of cache misses, we have to ensure that each variable resides in a different cache line.
This allows us to avoid false-sharing. Java 8 has introduced @Contended annotation.
At runtime the JVM optimizes field layout. At the JVM’s discretion,
those fields annotated as contended are given extra padding so they do not share cache lines with other fields that are likely to be independently accessed.
This helps to avoid cache contention across multiple threads.
The class with extra padding:
public class Counter {
@Contended
private volatile long counterA = 0L;
@Contended
private volatile long counterB = 0L;
//...
}And its memory layout
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 132 (alignment/padding gap)
144 8 long Counter.counterA N/A
152 128 (alignment/padding gap)
280 8 long Counter.counterB N/A
Instance size: 288 bytes
Space losses: 260 bytes internal + 0 bytes external = 260 bytes total
By default, @Contended adds 128 bytes padding before each annotated field.
The size of padding could be configurable through -XX:ContendedPaddingWidth tuning flag.
Remember, if you want to use @Contended annotation, you have to use the -XX:-RestrictContended tuning flag to allow using this annotation outside the JDK internal.
Now, we are sure that each counter field is fetched in a separate cache line and we can expect a performance boost:
Benchmark Mode Cnt Score Error Units
FalseSharingBenchmark.contended avgt 20 6,765 ± 0,063 ns/op
FalseSharingBenchmark.contended:contendedIncrementA avgt 20 6,765 ± 0,063 ns/op
FalseSharingBenchmark.contended:contendedIncrementB avgt 20 6,765 ± 0,063 ns/op
FalseSharingBenchmark.falseSharing avgt 20 50,828 ± 0,626 ns/op
FalseSharingBenchmark.falseSharing:incrementCounterA avgt 20 50,928 ± 1,156 ns/op
FalseSharingBenchmark.falseSharing:incrementCounterB avgt 20 50,728 ± 1,741 ns/op
Adding @Contended solved the false-sharing problem and reduced significantly execution time: 6.765 ns vs 50.825 ns.
Conclusion
@Contendedsolves problem of false-sharing- This annotation is used in multiple internal java classes. Notable mentions:
Thread,ForkJoinPool,ConccurentHashMap. - You should know memory layout of objects
- Remember, this approach is not a silver bullet.
The examples are available on GitHub.
Resources
- https://en.wikipedia.org/wiki/Cache_prefetching
- https://dzone.com/articles/what-false-sharing-is-and-how-jvm-prevents-it
- https://www.baeldung.com/java-false-sharing-contended
- https://dzone.com/articles/false-sharing